Mysql Indices
Ir a la navegación
Ir a la búsqueda

Sumario
Introdución
- Nota: Muchos de los ejemplos que se desarrollan en esta sección hacen uso de la base de datos employees, la cual indicamos como instalarla en otra sección anterior
- Ya vimos que podemos activar el registro de consultar lentas para determinar cuales son las consultas que más ralentizan el Mysql.
- Cuando descubramos una de esas sentencias, tendremos que analizarla para ver la razón.
- Una posible causa será el no utilizar índices.
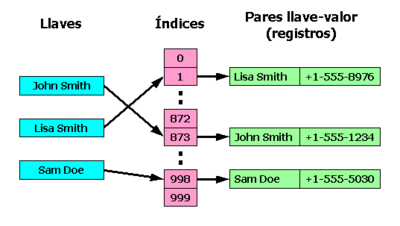
- Un índice es una estructura de datos en la cual los valores guardados son los datos de una o más columnas de una tabla de forma ordenada. Cada entrada del índice apuntará a la ubicación del registro en la tabla.
- De esta forma, la búsqueda de registros por un campo indexado será mucho más rápida que si no lo está.
- Como en todo, el uso de registros lleva aparejado ciertos problemas (sino fuera así podríamos crear índices para todas las columnas de una tabla):
- Es una estructura de datos que ocupa espacio a mayores del espacio de la propia tabla.
- En caso de operaciones de inserción, borrado o modificación el índice se debe rehacer con la consiguiente carga de trabajo para el gestor.
- Toda clave primaria debe tener un índice asociado (de hecho se crea automaticamente).
- También deberían tenerlo las claves foráneas.
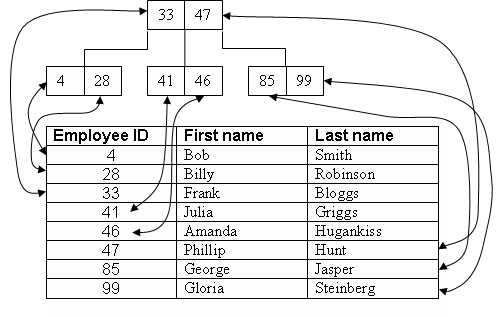
- Un ejemplo obtenido de la wiki:

- En este ejemplo, la clave primaria tiene asociado un índice de tipo BTREE, en el que las claves están ordenadas, estando al lado izquierdo las menores y al lado derecho las mayores con respecto al valor referenciado de un nodo dado.
- ¿ Cuando voy a hacer uso de índices ?
- En cláusulas WHERE
- En cláusulas ORDER BY
- Si tengo una orden SQL como:
- SELECT nombre FROM ALUMNOS WHERE edad between 10 and 20
- Tardará menos en ejecutarse si tengo un índice asociado a la edad que si no lo tengo.
Crear índices
- Podemos crear un índice de tres formas:
- Con la orden SQL CREATE INDEX
- Con la orden SQL ALTER TABLE y la opción ADD INDEX.
- Con la orden SQL CREATE TABLE y la opción INDEX | KEY (se puede emplear una u otra).
- Veamos un ejemplo sobre una supuesta tabla Alumnos sobre la que queramos indexar su nombre:
CREATE INDEX idx_Alumnos_nombre ON Alumnos (nombre)
- Siendo Alumnos el nombre de la tabla y nombre la columna a indexar.
ALTER TABLE Alumnos ADD INDEX idx_Alumnos_nombre (nombre)
- Siendo Alumnos el nombre de la tabla y nombre la columna a indexar.
- Algunos de los modificadores que podemos añadir a la creación de un índice:
- UNIQUE: índice formado por campos cuyo valor no puede repetirse.
- PRIMARY: Es el índice que conforma la clave primaria de una tabla. Los valores no pueden repetirse. Es recomendable que sea numérica y en caso de no existir, se debe crear una columna de tipo 'autonumérico'.
- full-text: Es un tipo de índice 'especial' que se aplica a campos de texto de gran tamaño, como el tipo TEXT y sus variantes, aunque también puede realizarse sobre char y varchar. Al crear un índice de este tipo, cada una de las palabras del texto es 'indexada' para poder hacer búsquedas en las que se busca sólo alguna de las palabras del mismo. Esto se realiza haciendo uso de la orden SQL MATCH(). A diferencia de LIKE, este comando busca por palabras y permite buscar en varias columnas, indicar si deben aparecer ciertas palabras en la columna o que no aparezcan ciertas otras,...
- SPATIAL: Son índices usados para tipos de datos espaciales como LINE o CURVE.
Modificar índices
- No es posible.
- Podemos utilizar la orden SQL ALTER TABLE con la opción ALTER INDEX para hacer el índice visible o invisible.
- Esto hará que el optimizador de consultas no lo use (invisible) o lo tenga en cuenta (visible).
- Sólo se puede utilizar en NDB CLUSTER.
- Un ejemplo:
ALTER TABLE Alumnos ALTER INDEX idx_Alumnos_nombre INVISBLE
- Siendo Alumnos el nombre de la tabla.
Borrar índices
- Podemos usar la orden SQL DROP INDEX.
- Un ejemplo:
DROP INDEX idx_Alumnos_nombre ON Alumnos
- Siendo Alumnos el nombre de la tabla.
Tipos de índices
Parciales
- Como comentamos en la introducción, los índices van a ocupar espacio en disco.
- Una columna de 200 caracteres de ancho (200 bytes) y con 5 millones de registros, si hacemos un índice sobre ella, ocupará 1.000.000.000 de bytes = 953MB
- Para evitarlo podemos crear un índice parcial, es decir, un índice sobre una parte del tamaño de la columna.
CREATE INDEX idx_Alumnos_direccion ON Alumnos (direccion(100))
- En este caso estamos creando un índice de la mitad del tamaño de la columna (100 caracteres) por lo tanto ocupará 953/2 = 476MB
- Se pueden crear sobre columnas de tipo CHAR, VARCHAR y TEXT.
- En el caso de TEXT es obligatorio indicarlo.
- También con los tipos de datos BINARY, VARBINARY y BLOG, pero en este caso indicamos el número de bytes. También es obligatorio.
Multicolumna
- Este tipo de índices abarca más de una columna.
- Un caso típico podría ser el de columnas nombre y apellidos.
- Si quiero crear un índice por apellidos y dentro de apellidos que ordene por nombre, crearía un único índice con las dos columnas, de la forma:
CREATE INDEX idx_Alumnos_nombre_apellidos ON Alumnos (apellidos(100),nombre)
- Nota Fijarse que el orden de las columnas en el índice es importante. No es lo mismo crear un índice de 'nombre-apellidos' que de 'apellidos-nombre'.
- Si se realizan consultas en los que se busca por varios campos, se debe de crear un índice multicolumna mejor que varios índices parciales
- Veremos en el siguiente punto de la Wiki cual es el mejor orden
Secundarios o clusters
- Cuando creamos una clave primaria, realmente estamos creando un índice sobre las columnas que conforman la clave primaria, un tipo de índice que impide que haya dos valores iguales.
- Al crearlo, Mysql ordena físicamente los registros para que coincidan con el índice, de tal forma que índice y registro están 'unidos'. El registro se guarda junto a su clave primaria.
- Así, si tengo creado como índice de clave primaria una columna id, físicamente los registros estarán:
ID-------Nombre 1--------Angel 2--------Maria 3--------Juan 4--------Ana
- Este tipo de índice se denomina cluster.
- En una tabla, como vimos, podemos crear otros índices. Cuando usamos INNODB como motor de almacenamiento, éstos guardan el valor de la clave primaria para buscar el registro, a parte del valor del índice creado. Este tipo de índices se denominan índices secundarios o no clusterizados.
- En el ejemplo anterior, si creamos un índice sobre la columna Nombre tendremos:
Nombre-------ID Ana----------4 Angel--------1 Juan---------3 Maria--------2
- Para recuperar un registro cuando usamos un índice secundario, necesitamos dos operaciones de disco, una para buscar el valor en la tabla del índice y otra para buscar el registro a partir de la clave primaria.
- En el motor MyISAM pasa lo mismo, pero la diferencia es que los índices se guardan en archivos separados y el valor asociado al índice no es la clave primaria, sino el valor desplazamiento (offset) del registro en la tabla.
- Visto lo anterior es importante elegir bien la clave primaria:
- Debemos elegir un campo que no implique modificaciones, ya que será necesario una reordenación de los registro.
- Además es mejor que tenga un tamaño pequeño, ya que, si por ejemplo es una cadena de 100 caracteres, estamos guardando en todos los índices secundarios 100 caracteres en cada entrada del índice.
Estructura de índices
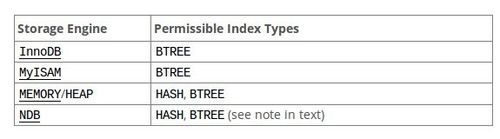
- Si miramos la sintaxis de la orden SQL CREATE INDEX, en la opción index_type podemos escoger entre BTREE o HASH
BTREE
- Es una estructura en forma de árbol-b (b-tree) balanceado (se intenta que haya una cantidad similar de nodos a un lado y a otro del árbol.
- Cada nodo del árbol posee un valor del índice, ordenado. Cada nodo 'apunta' a registros del disco.
- La cantidad de nodos hijos permitida es variable (si fuera dos, tendríamos un árbol binario, por ejemplo).
- Su uso es adecuado para consultas basadas en operadores de comparación (<,>, =, < >) y rangos de valores (between).
HASH
- Se basan en el uso de una función de HASH. Este tipo de función, transforma una entrada (en nuestro caso, la columna de la tabla sobre la que vamos a crear un índice) en un valor único.
- Ese valor único es guarda en una tabla, y cada entrada de esa tabla tiene asociada el valor de la clave primaria para buscar el registro.

- La estructura de HASH es más rápida que la B-Tree cuando la utilizamos para comparar valores de la forma: columna = valor en la cláusula WHERE.
- Presenta los siguientes inconvenientes:
- Puede haber colisiones (en el caso de dos valores, al aplicarse la función de HASH den el mismo resultado)
- En el caso de búsquedas por rango, es más lenta que en el caso de B-TREE.
- En el caso de cláusulas ORDER BY, Mysql no puede emplear índices HASH.
- Este tipo de algoritmo sólo se puede utilizar en los motores de bases de datos MEMORY/HEAP/NDP

- Más información en este enlace.
Trabajando con índices
- Para obtener información sobre los índices creados en una tabla, usaremos la orden SQL SHOW INDEX.
- Veamos un ejemplo:
SHOW INDEX FROM employees.departments;
- Obtendrías información sobre los índices creados en la tabla 'departments' de la base de datos 'employees' (la base de datos se podría omitir y buscaría la tabla en la base de datos activa).

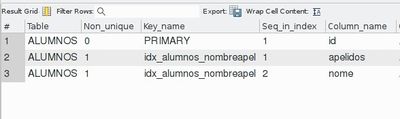
- La salida indica lo siguiente:
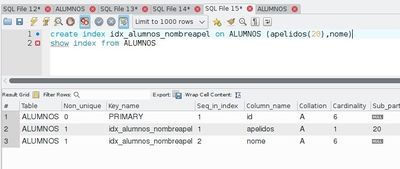
- Table: Nombre de la tabla que contiene el índice.
- Non_unique: Indica si el índice es UNIQUE/PRIMARY o no (1 o 0) (recordar que todo índice PRIMARY es UNIQUE).
- Key_name: Nombre del índice.
- Seq_in_index: Indica el orden del índice dentro de un índice multicolumna.
- En el ejemplo siguiente, está creado un índice sobre las columnas 'apellidos' y 'nombre' en ese orden:
- .
- Column_name: Nombre de la columna a la que hace referencia el índice.
- Collation: Forma en como está ordenado el índice. NULL indica sin ordenar y 'A' indica de forma ascendente.
- Cardinality: Indica el número de entradas que está almacenando el índice para esa columna de forma aproximada.
- Sub_part: En caso de que el índice no se cree sobre todo la columna, sino sobre una parte de su tamaño, indicaría el número de caracteres/bytes que conforman el índice:
- .
- Packed: Indica si la columna está empaquetada. NULL indica que no lo está.
- NULL: Indica si la columna admite valores NULOS.
- Index_type: Estructura de datos del índice. Puede ser btree, hash, fulltext o rtree.


Optimizando los índices
- Los índices no pueden ser actualizados y es necesario borrarlos y volverlos a crear.
- Además, los índices generan ciertas estadísticas que son utilizadas por el optimizador de consultas para determinar cual es la mejor forma de obtener los resultados de una consulta.
- Por estas dos razones, debemos de utilizar uno de estos dos comandos:
- El comando OPTIMIZE TABLE cuando trabajamos con tablas que han sufrido muchas operaciones modificando las columnas asociadas a sus índices (borrados, actualizaciones, inserciones).
- Este comando va a desfragmentar la tabla y a actualizar y reordenar sus índices. Sólo se puede aplicar sobre motores INNODB, MYISAM y Archive.
- Tendrá el efecto de recuperar el espacio de disco que una tabla ya no usa (después de hacer un borrado de muchas filas).
- Recrear los índices y volver a generar la información necesaria para que el optimizador de consultas determine cuando hacer uso del mismo.
- El comando ANALYZE TABLE cuando trabajamos con tablas que han sufrido muchas operaciones modificando las columnas asociadas a sus índices (borrados, actualizaciones, inserciones).
- A diferencia del anterior, este comando sólo recrea los índices de la tabla pero no recupera el espacio de disco que ya no utilice.
- OPTIMIZE TABLE en el caso del motor INNODB, lo que hace 'realmente' es crear una tabla copia de la tabla a optimizar, borra la original y renombra la nueva, haciendo después un ANALYZE TABLE.
- Por lo tanto este comando sirve también para 'reclamar' el espacio que ya no utiliza una tabla (al borrarse registros, el tamaño físico de la tabla se mantiene).
- Hay que tener cuidado ya que va a necesitar el doble de tamaño en disco (de lo que ocupa la tabla) para realizar la operación (en el caso de recrear los índices).
- La reducción de espacio sólo funcionará si la variable del sistema innodb_file_per_table está a ON (valor por defecto).
- Nota:
- Cuando se ejecuta este comando con el motor InnoDB saldrá un aviso con el siguiente texto: Table does not support optimize, doing recreate + analyze instead.
- No hacer caso al mismo ya que lo que indica es que el motor InnoDB no va a hacer lo que se hacía con el motor MyISAM para optimizar la tabla.
- Debemos de tener cuidado cuando ejecutamos el comando ya que la tabla queda 'bloqueada' hasta que finalice la optimización.
- Por defecto. si está activo el registro binario de log, las operaciones realizadas por el comando anterior son guardadas en dicho fichero. Si queremos que esto no ocurra, tendremos que llamar al comando con la opción 'LOCAL' o 'NO_WRITE_TO_BINLOG'. Esto es así para que en caso de un entorno de maestro-esclavos, los cambios no sean replicados a los esclavos.
- Por tanto, tendremos que ejecutar operaciones de optimización sobre tablas que se modifiquen habitualmente (operaciones de borrado, inserción y modificación sobre los datos asociados al índice).
- Veamos un ejemplo:
OPTIMIZE TABLE ALUMNOS;
ANALYZE TABLE ALUMNOS;
- Según esta documentación, en el caso de tener índices secundarios es mejor borrarlos, optimizar la tabla y volver a crearlos.
Ejercicios propuestos
- Sobre la base de datos employees
- Dada la siguiente consulta SQL:
select * from employees where last_name='Koblick' and first_name like 'Chi%'
- Reflexiona cual debería ser el índice creado, (last_name,first_name) o (first_name,last_name)
- Dada la siguiente consulta SQL:
select * from salaries order by from_date;
- Ejecuta dicha sentencia y comprueba el tiempo de ejecución.
- Averigua cuales son los índices asociados a la tabla. Si ya existe un índice sobre la columna 'from_date' ¿ por qué no funciona adecuadamente ?
- Crea el índice adecuado y comprueba cual es el tiempo ahora.
- Muestra los índices creados en la tabla.
- Borra 1.000.000 filas (haz una copia antes de los datos de la tabla. Vas a tener que poner la variable secure-file-priv="" dentro del archivo de configuración y reiniciar el servidor) y muestra la información sobre los índices asociados a la tabla. ¿ Qué diferencias encuentras?
- Para borrar puedes utilizar esta orden SQL: DELETE FROM employees.salaries WHERE YEAR(from_date)<1995
- Comprueba el tamaño de la tabla:
SELECT table_name AS `Table`, round(((data_length + index_length) / 1024 / 1024), 2) `Size in MB` FROM information_schema.TABLES WHERE table_schema = "$DB_NAME" AND table_name = "$TABLE_NAME";
- Consultado tamaños de tabla

Pulsando el botón derecho sobre la base de datos escogemos la opción Schema Inspector.

Pulsamos en la pestaña Tables para ver la información de todas las tablas de la base de datos.


{kind=link}
- Realiza una optimización de la tabla y sus índices.
- Recupera los registros borrados.
- Crea en SQL una tabla en memoria que sea una copia de la tabla employees (botón derecho sobre la tabla, obtener la orden create y modificar el motor de almacenamiento):
CREATE TABLE `employees_m` ( `emp_no` int(11) NOT NULL, `birth_date` date NOT NULL, `first_name` varchar(14) NOT NULL, `last_name` varchar(16) NOT NULL, `gender` enum('M','F') NOT NULL, `hire_date` date NOT NULL, PRIMARY KEY (`emp_no`) ) ENGINE=MEMORY;
- Modifica la variable del sistema que controla el tamaño máximo de memoria por tabla para que quepan los datos de la tabla employees más los índices a crear (cuenta el número de registros y multiplica por el número de filas. Para la estructura del registro ten en cuenta que se guarda el campo más la clave primaria)
- Pasa los datos de la tabla 'employees' a la tabla 'employees_m' con la orden SELECT campos FROM TABLA INTO NUEVA_TABLA
- Comprueba el tiempo de ejecución de la orden SQL: SELECT * FROM employees.employees_m where first_name='Parto'
- Crea el tipo de índice que mejor se ajuste al tipo de sentencia. Comprueba el nuevo tiempo de ejecución.
- Crea el otro tipo de índice (borrando el anterior) y compara los tiempos de ejecución de la sentencia (mirar columna Fetch, el la parte baja, donde muestra el número de filas devueltas)
Enlace a la página principal de la UD4
Enlace a la página principal del curso
-- Ángel D. Fernández González -- (2017).